StreamPipes Concepts
To understand how StreamPipes works, it is helpful to understand a few core concepts, which are illustrated below. These encompass the entire data journey within StreamPipes: Starting with data collection (adapters), through data exchange (data streams) and data processing (data processors and pipelines), to data persistence and distribution (data sinks).
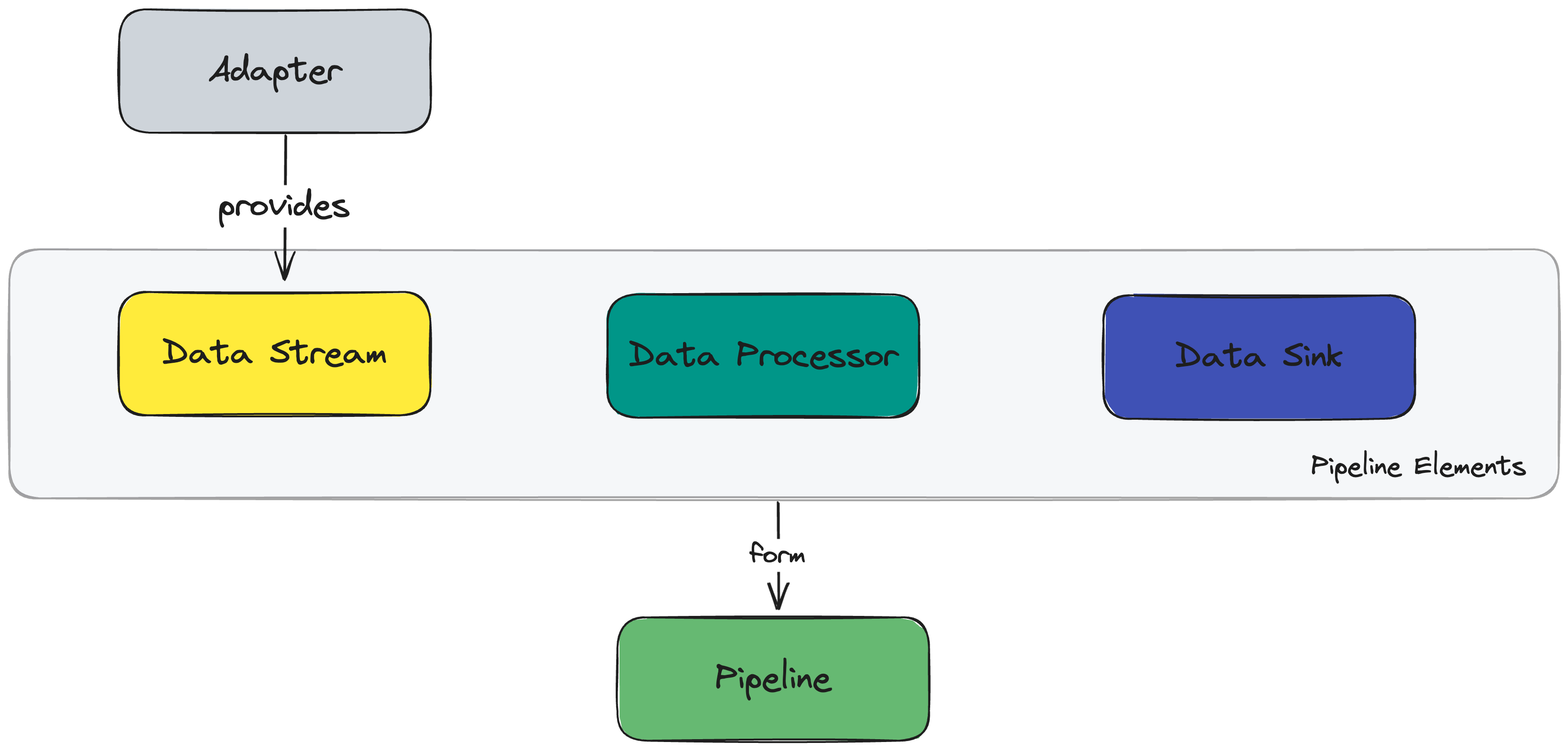
Adapter
An adapter connects to any external data source (e.g., OPC-UA, MQTT, S7 PLC, Modbus) and forwards the events it receives to the internal StreamPipes system. Adapters can either be created by using a predefined adapter for a data source available in our marketplace StreamPipes Connect. An overview of all available adapters can be found under the menu bar 📚 Pipeline Elements. When you select one of these adapters, you can easily connect to the data source using an intuitive and convenient UI dialog (see the Connect section for more details). Alternatively, you can define your own adapter by using the provided Software Development Kit (SDK). Creating an adapter is always the first step when you want to get data into StreamPipes and process it further.
Data Stream
Data streams are the primary source for working with events in StreamPipes.
A stream is an ordered sequence of events, where an event typically consists of one or more observation values and additional metadata.
The structure (or schema as we call it) of an event provided by a data stream is stored in StreamPipes' internal semantic schema registry.
Data streams are primarily created by adapters, but can also be created by a StreamPipes Function.
Data Processor
Data processors in StreamPipes transform one or more input streams into an output stream.
Such transformations can be simple, such as filtering based on a predefined rule, or more complex, such as applying rule-based or learning-based algorithms to the data.
Data processors can be applied to any data stream that meets the input requirements of a processor.
In addition, most processors can be configured by providing custom parameters directly in the user interface.
Processing elements define stream requirements, which are a set of minimum characteristics that an incoming event stream must provide.
Data processors can maintain state or perform stateless operations.
Data Sink
Data sinks consume event streams similar to data processors, but do not provide an output data stream. As such, data sinks typically perform some action or trigger a visualization as a result of a stream transformation. Similar to data processors, sinks also require the presence of specific input requirements from each bound data stream and can be customized. StreamPipes provides several internal data sinks, for example, to generate notifications, visualize live data, or persist historical data from incoming streams. In addition, StreamPipes provides several data sinks to forward data streams to external systems such as databases.
Pipeline
A pipeline in Apache StreamPipes describes the transformation process from a data stream to a data sink. Typically, a pipeline consists of at least one data stream, zero or more data processors, and at least one data sink. Pipelines are created graphically by users using the Pipeline Editor and can be started and stopped at any time.