Architecture
Architecture
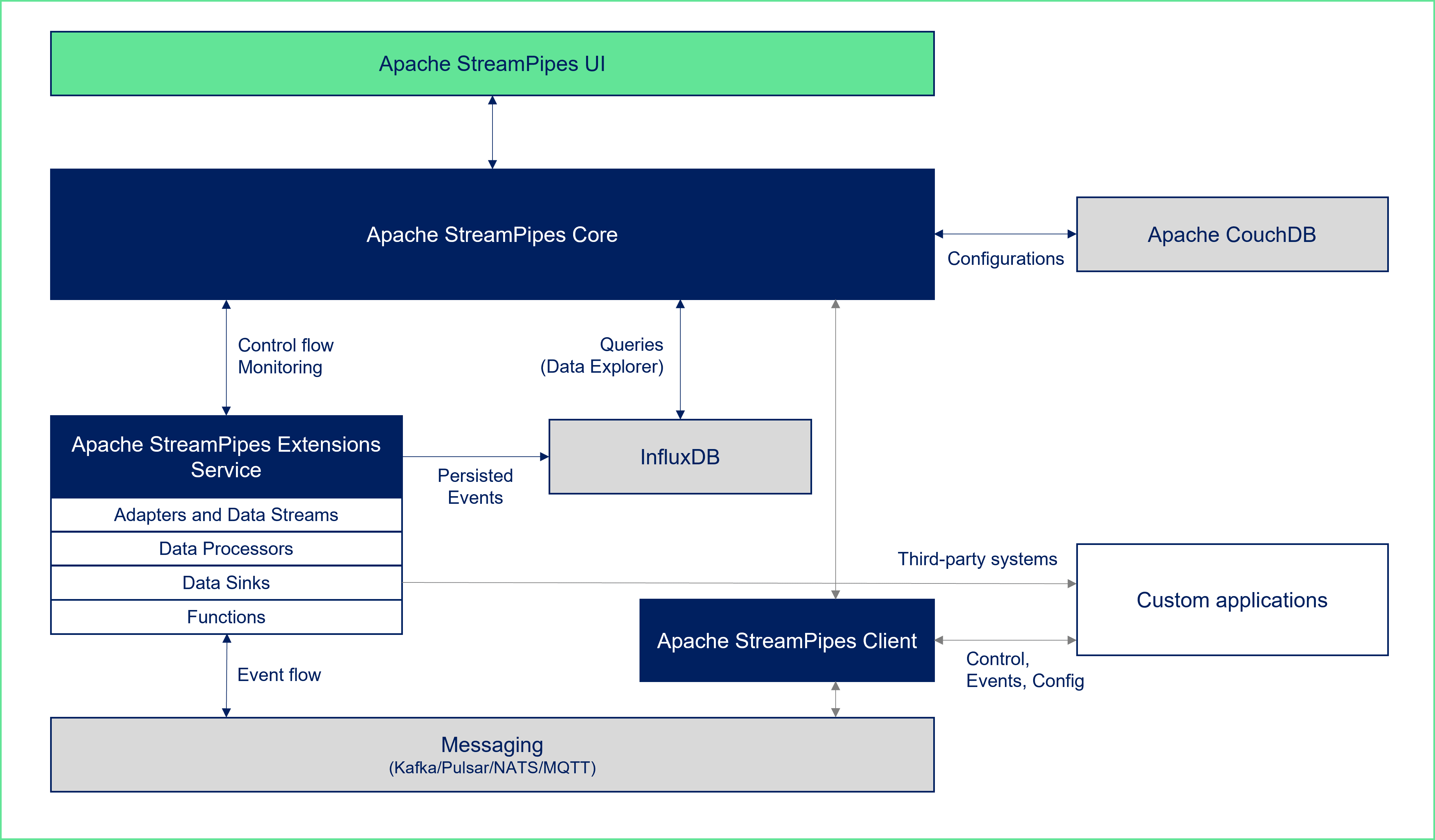
Apache StreamPipes implements a microservice architecture as shown in the figure above.
StreamPipes Core
The StreamPipes Core is the central component to manage all StreamPipes resources. It delegates the management of adapters, pipeline elements, pipelines and functions to registered extensions services (see below) and monitors the execution of extensions. The Core also provides internal REST interfaces to communicate with the user interface, as well as public REST interfaces that can be used by external applications and StreamPipes clients.
Configuration and user data are stored in an Apache CouchDB database.
StreamPipes Extensions
An Apache StreamPipes extensions service is a microservice which contains the implementation of specific adapters, data streams, data processors, data sinks and functions. Multiple extension services can be part of a single StreamPipes installation. Each service might provide its own set of extensions. Extensions services register at the StreamPipes Core at startup. Users are able to install all or a subset of extensions of each service. This allows StreamPipes to be extended at runtime by starting a new service with additional extensions.
Extensions can be built using the SDK (see Extending StreamPipes). Extensions services can be provided either in Java or in Python.
As of version 0.93.0, the Python SDK supports functions only. If you would like to develop pipeline elements in Python as well, let us know in a Github discussions comment, so that we can better prioritize development.
An extensions service interacts with the core by receiving control messages to invoke or detach an extension. In addition, the core regularly fetches monitoring and log data from each registered extensions service.
StreamPipes Client
The Apache StreamPipes Client is a lightweight library for Java and Python which can be used to interact with StreamPipes resources programmatically. For instance, users use the client to influence the control flow of pipelines, to download raw data from the data lake APIs or to realize custom applications with live data.
Third-party systems
In addition to the core components, an Apache StreamPipes version uses several third-party services, which are part of the standard installation.
- Configurations and user data is stored in an Apache CouchDB database.
- Time-series data is stored in an InfluxDB database.
- Events are exchanged over a messaging system. Users can choose from various messaging systems that StreamPipes supports. Currently, we support Apache Kafka, Apache Pulsar, MQTT and NATS. The selection of the right messaging system depends on the use case. See Messaging for more information.
Versions prior to 0.93.0 included Consul for service discovery and registration. Starting from 0.93.0 onwards, we switched to an internal service discovery mechanism.
All mentioned third-party services are part of the default installation and are auto-configured during the installation process.
Programming Languages
Apache StreamPipes is mainly written in Java. Services are based on Spring Boot. The included Python integration is written in Python.
The user interface is mainly written in TypeScript using the Angular framework.
Data Model
Internally, Apache StreamPipes realizes a stream processing layer where events are continuously exchanged over a messaging system. When building a pipeline, data processors consume data from a topic assigned by the core and publish data back to another topic, which is also assigned by the core.
At runtime, events have a flat and easily understandable data structure, consisting of key/value pairs. Events are serialized in JSON, although StreamPipes can be configured to use other (binary) message formats.
This allows for easy integration with other systems which want to consume data from Streampipes, since an event could look as simple as this:
{
"timestamp": 1234556,
"deviceId": "ABC",
"temperature": 37.5
}
However, this wouldn't be very expressive, right? To assist users, StreamPipes provides a rich description layer for events. So under the hood, for the temperature field shown above StreamPipes can also store the following:
{
"label": "Temperature",
"description": "Measures the temperature during leakage tests",
"measurementUnit": "https://qudt.org/vocab/unit/DEG_C",
"runtimeName": "temperature",
"runtimeType": "xsd:float",
"semanticType": "https://my-company-vocabulary/leakage-test-temperature"
}
By dividing the description layer from the runtime representation, we get a good trade-off between expressivity, readability for humans and lightweight runtime message formats. The schema is stored in an internal schema registry and available to the client APIs and user interface views to improve validation and user guidance.
StreamPipes also supports arrays and nested structures, although we recommend using flat events where possible to ease integration with downstream systems (such as time-series storage).