Architecture
The following picture illustrates the high-level architecture of StreamPipes:
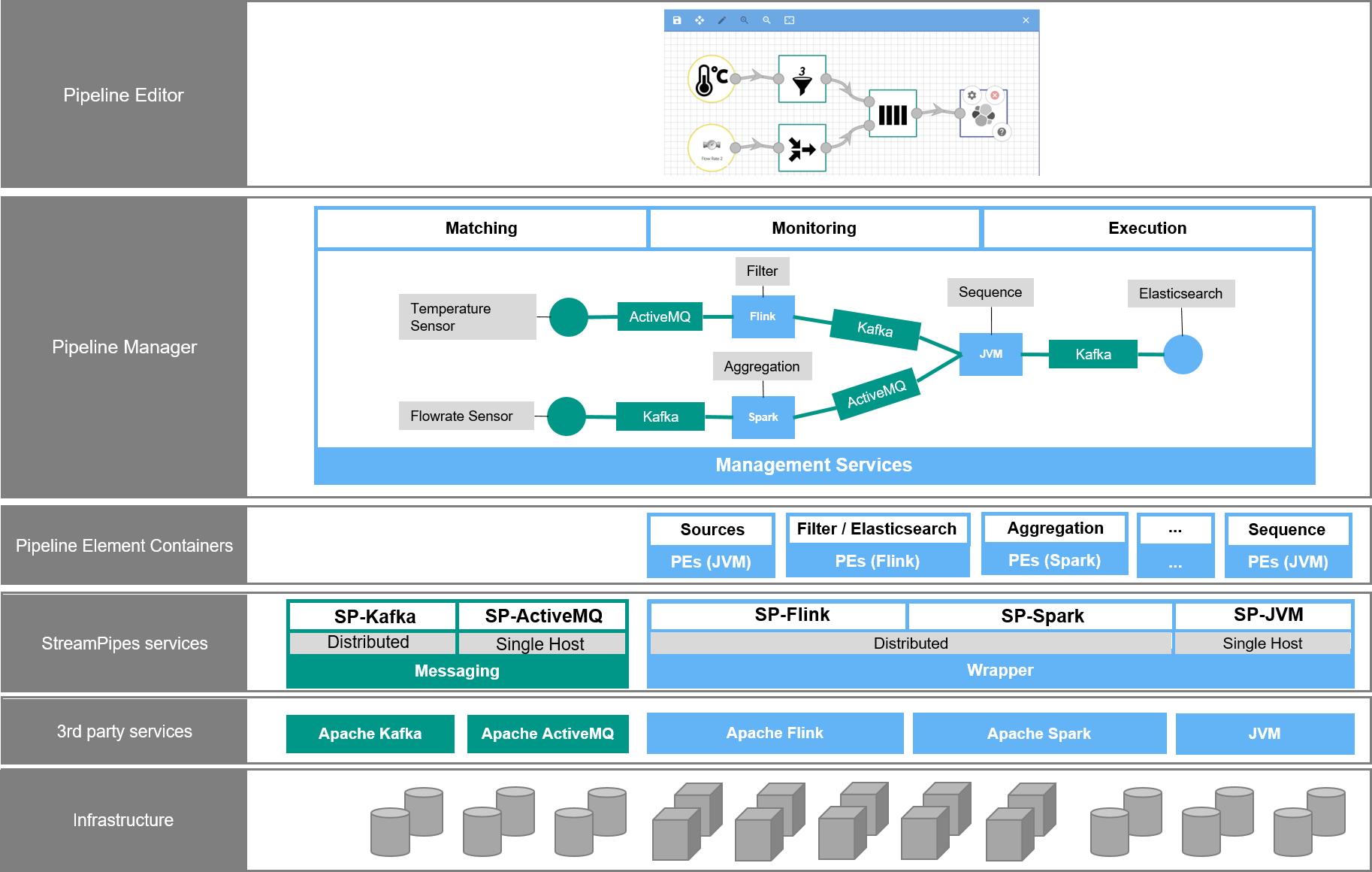
Users mainly interact (besides other UI components) with the Pipeline Editor to create stream processing pipelines based on data streams, data processors and data sinks. These reusable pipeline elements are provided by self-contained pipeline element containers, each of them having a semantic description that specifies their characteristics (e.g., input, output and required user input for data processors). Each pipeline element container has a REST endpoint that provides these characteristics as a JSON-LD document.
Pipeline element containers are built using one of several provided wrappers. Wrappers abstract from the underlying runtime stream processing framework. Currently, the StreamPipes framework provides wrappers for Apache Flink, Esper and algorithms running directly on the JVM.
The pipeline manager manages the definition and execution of pipelines. When creating pipelines, the manager continuously matches the pipeline against its semantic description and provides user guidance in form of recommendations. Once a pipeline is started, the pipeline manager invokes the corresponding pipeline element containers. The container prepares the actual execution logic and submits the program to the underlying execution engine, e.g., the program is deployed in the Apache Flink cluster.
Pipeline elements exchange data using one or more message brokers and protocols (e.g., Kafka or MQTT). StreamPipes does not rely on a specific broker or message format, but negotiates suitable brokers based on the capabilities of connected pipeline elements.
Thus, StreamPipes provides a higher-level abstraction of existing stream processing technology by leveraging domain experts to create streaming analytics pipelines in a self-service manner.
Semantic description
Pipeline elements in StreamPipes are meant to be reusable:
- Data processors and data sink are generic (or domain-specific) elements that express their requirements and are able to operate on any stream that satisfies these requirements.
- Data processors and data sinks can be manually configured by offering possible configuration parameters which users can individually define when creating pipelines.
- Data streams can be connected to any data processor or data sink that matches the capabilities of the stream.
When users create pipelines by connecting a data stream with a data processor (or further processors), the pipeline manager matches the input stream of a data processor against its requirements. This matching is performed based on the _semantic description of each element. The semantic description (technically an RDF graph serialized as JSON-LD) can be best understood by seeing it as an envelope around a pipeline element. It only provides metadata information, while we don't rely on any RDF at runtime for exchanging events between pipeline elements. While RDF-based metadata ensures good understanding of stream capabilities, lightweight event formats at runtime (such as JSON or Thrift) ensure fast processing of events.
Let's look at an example stream that produces a continuous stream of vehicle positions as illustrated below:
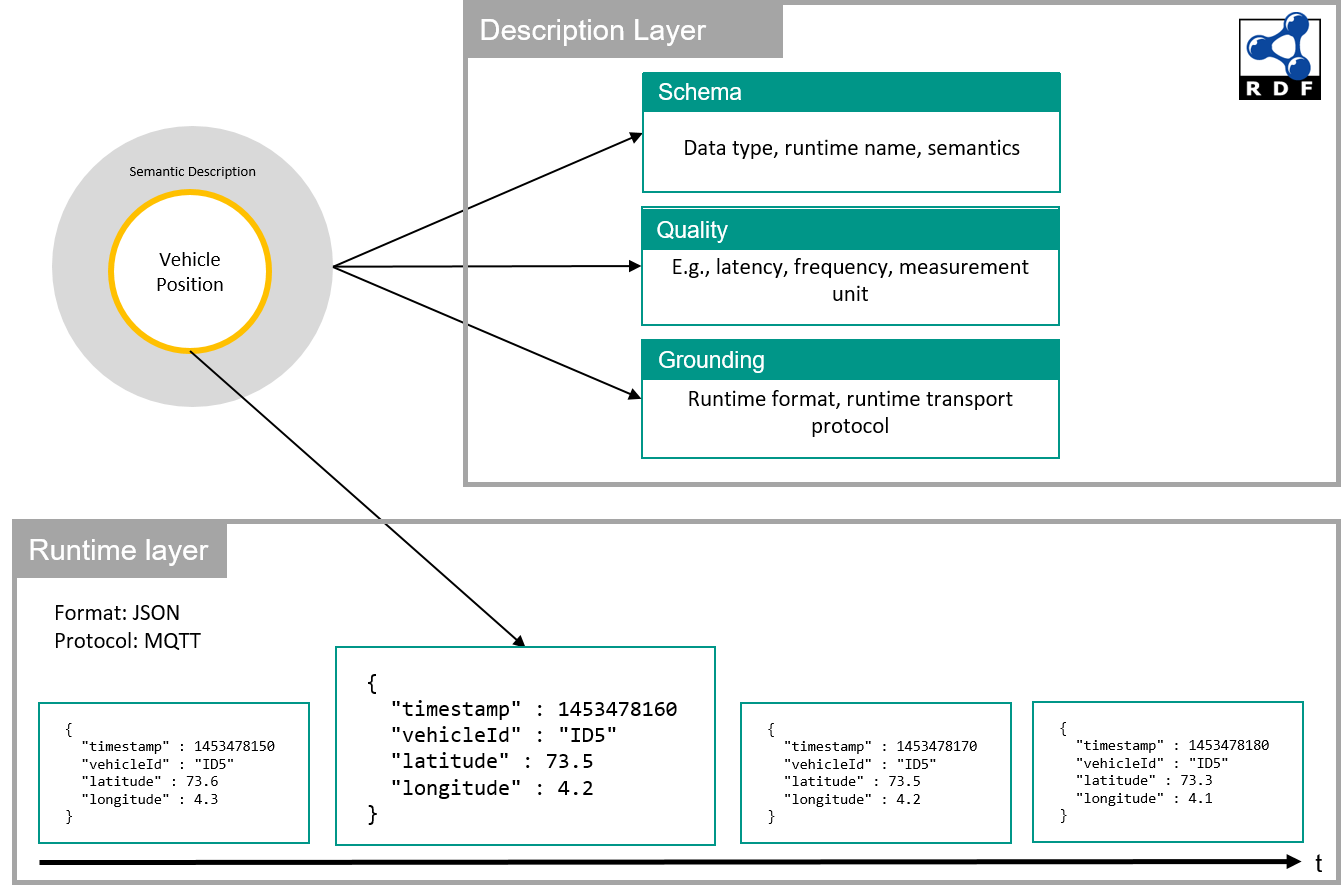
While the runtime layer produces plain JSON by submitting actual values of the position and the vehicle's plate number, the description layer describes various characteristics of the stream: For instance, it defines the event schema (including, besides the data type and the runtime name of each property also a more fine-grained meaning of the property), quality aspects (e.g., the measurement unit of a property or the frequency) and the grounding (e.g., the format used at runtime and the communication protocol used for transmitting events).
The same accounts for data processors and data sinks:
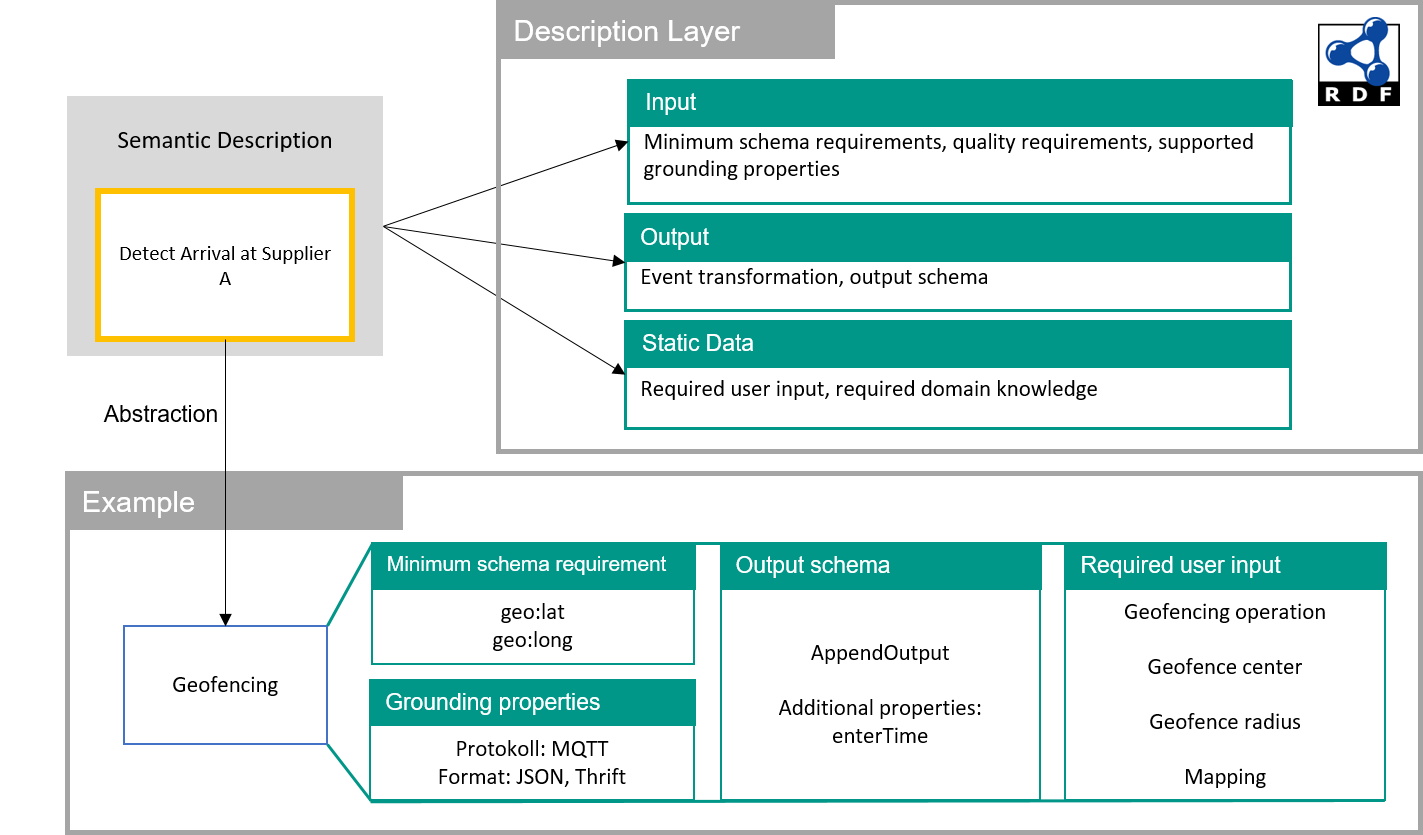
Data processors (and, with some differences, data sinks) are annotated by providing metadata information on their required input and output. For instance, we can define minimum schema requirements (such as geospatial coordinates that need to be provided by any stream that is connected to a processor), but also required (minimum or maximum) quality levels and supported transport protocols and formats. In addition, required configuration parameters users can define during the pipeline definition process are provided by the semantic description.
Once new pipeline elements are imported into StreamPipes, we store all information provided by the description layer in a central repository and use this information to guide useres through the pipeline definition process.
Don't worry - you will never be required to model RDF by yourself. Our SDK provides convenience methods that help creating the description automatically.